Wstęp
Dzisiejszy wpis będzie nieco inny niż przeważnie. Tym razem nie przybywamy z nowym modelem, ale z opisem metody RAG. Metoda jest ogólnie znana, dlatego ten wpis będzie bardziej w kontekście problemów, które pojawiają się podczas realizacji systemów wykorzystujących RAG’a, niż opis samej metody.
Opowiadając w kilku słowach czym jest RAG, można powiedzieć, że jest to metoda wyszukiwania informacji połączona (w warstwie prezentacji wyników) z modelem generatywnym/modelem instrukcji. Mechanizm wyszukiwania oraz zmiany kolejności wyszukanych wyników jest odpowiedzialny za odnalezienie fragmentów tekstów, w których znajduje się odpowiedź na pytanie zadane przez użytkownika. Następnie, fragmenty tekstów aplikowane są do modelu generatywnego w taki sposób, aby model na ich podstawie odpowiedział na pytanie zadane przez użytkownika. I tyle w skrócie 😉
Do czego, w takim razie, można wykorzystać RAGa? Z racji, że jest to metoda wyszukiwania, to oczywiście do wszelakiego rodzaju wyszukiwarek. Jednak ważnym aspektem, który odróżnia RAGa od standardowego sposobu przeszukiwania kolekcji dokumentów, jest wprowadzenie modelu generatywnego (GenAI) do udzielenia końcowej odpowiedzi dla użytkownika. Dzięki dokładności samej wyszukiwarki oraz zdolności modelu GenAI do odpowiadania na pytania na podstawie kontekstu, RAG idealnie nada się do wyszukiwania i podsumowywania informacji rozproszonej w wielu dokumentach. Dodatkowo, dzięki GenAI oraz ich przeznaczeniu do prowadzenia konwersacji na czacie, mamy możliwość wpływania na końcową postać odpowiedzi przy zadawaniu pytania. Dla przykładu wyobraźmy sobie, że mamy kolekcję dokumentów, w której gromadzimy teksty z różnymi opiniami użytkowników odnośnie różnych produktów. W tym przypadku RAG idealnie nadałby się do odpowiedzenia na pytanie:
Jakie są pozytywne, a jakie negatywne opinie na temat produktu XYZ? Podaj po trzy przykłady pozytywnych i negatywnych opinii oraz zaproponuj odpowiedzi na komentarz klienta.
Jak widać w przykładzie, do RAGa można podać nie tyklo hasło do wyszukania, ale i rozbudowaną instrukcję udzielenia odpowiedzi.
Na Rys. 1 przedstawiliśmy podział procesu RAG na mniejsze i konkretniejsze kroki. Znajduje się tam sześć głównych modułów, które symbolizują zagadnienia w całym potoku RAGa. Za pomocą czerwonej, przerywanej linii i czerwonej strzałki zaznaczona jest minimalna ścieżka w takim potoku. Zielona linia i zielona strzałka pokazuje optymalną ścieżkę w potoku, który można nazwać RAGiem. W tym wpisie, krótko opisaliśmy poszczególne kroki, a ich szczegółowe rozwinięcia będą publikowane w kolejnych wpisach.
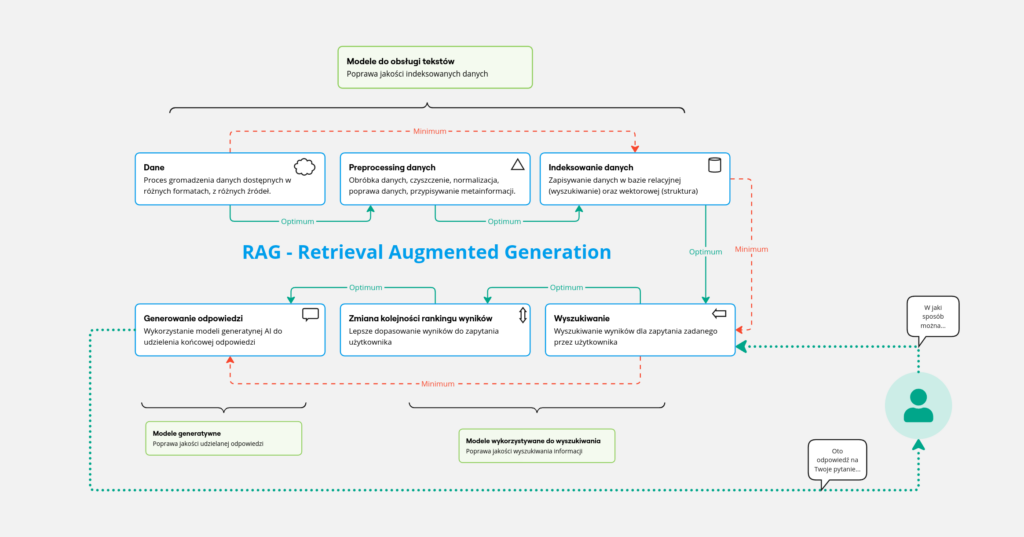
RAG w kawałkach
Dane
Dane, to podstawowy element każdego systemu, w którym wykorzystywane są metody uczenia maszynowego (ML). W zależności od problemu, który taki system ML realizuje, należy dostarczyć mu odpowiednie dane. W przypadku RAGa – dane, to wszelakiego rodzaju teksty, w których znajdowane będą odpowiedzi. Może się zatem wydawać, że w dzisiejszych czasach w internecie przecież można znaleźć wszystko i brak danych nie powinien być problemem… Po części tak, ale w większej części nie 😉
To właśnie mnogość danych wprowadza problem z ich lokalizacją, dostępnością na odpowiedniej licencji oraz ich jakością dowolnie rozumianą. Selekcja pochodzenia informacji z określonych źródeł, jakości samych danych, ich czytelność oraz szczegółowość, to bardzo istotny element całej układanki. Dodajmy do tego jeszcze różne formaty plików, w których zapisane są informacje (w tym format pdf), wtedy na starcie stajemy przed misją integracji różnych źródeł do wspólnego formatu. Pamiętajmy, że jeżeli do systemu wprowadzimy dane, które zawierają nieprawdziwe informacje, lub zawierają ich za mało, bądź są za mało szczegółowe, to system wykorzystujący metodę RAG będzie właśnie na ich podstawie podawał odpowiedzi, które mogą być błędne.
Warto raz jeszcze podkreślić, że końcowa odpowiedź systemu generowana jest na podstawie dostarczonych danych z wyszukiwarki. Zatem jeżeli w wyszukiwarce znajdą się nierzetelne dane, nieprawdziwe i małomerytoryczne informacje, to takie też odpowiedzi będziemy dostawać. Dlatego warto poświęcić czas na odpowiednie dobranie zbioru/utworzenie kolekcji dokumentów, na której będziemy działać, oraz zadbać o preprocessing danych.
Można zatem śmiało powiedzieć, że jakość odpowiedzi z takiego systemu, jest mocno determinowana jakością danych, z których taki system korzysta.
Preprocessing danych
Bardzo istotnym elementem systemu RAG jest preprocessing danych, czyli ich wstępna obróbka. Zanim dane trafią do dalszego procesu, warto wprowadzić pewien standard co do ich jakości. Wspomniana różnorodność zapisów danych powoduje problem z odpowiednim ich odczytywaniem. Automatyczne przetwarzanie danych pobranych ze stron www, plików docx, pdf wprowadza duży szum w danych. Z perspektywy systemu RAG ważne jest, aby dane zawierały istotne informacje. Przy automatycznym wczytywaniu danych, przykładowo z pliku pdf, odczytamy nie tylko istotne fragmenty, ale całą masę tekstu, łącznie z nagłówkami rozdziałów, poszatkowanymi danymi tabelarycznymi, bądź co gorsze — całkowicie nieczytelne dane, jak np. te (np. kiedy w pliku pdf są obrazki, które również jest ciężko OCRować):
4kV�#4T��##�_#�p��W#�_�|3��-�tg�\S�x�b�X��t�]*���\&/#��/�P�Oczywiście na taką sytuację ciężko jest coś poradzić, ale warto je wykrywać i nie dopuszczać danych dalej, już na etapie obróbki wstępnej. W naszym wcześniejszym wpisie przedstawiliśmy inny problem z plikami pdf. Po ich odczytaniu, dostajemy mocno zdeformowane dane, cytując przykład z wpisu:
Strona...Tytuł...%6%z%50%|.....Zdecydowana0większość0czerwonych.karłów$należy#do,typu,widmowego%M,%ale%zalicza^się^do^nich^także^wieleHgwiazdHpóźnychHpodtypówHtypuHwidmowegoHKHorazHrzadkoHwystępujące,,najsłabsze,gwiazdy,typu,L.,Maksimum%intensywności%emitowanego%światła%przypada%w%zakresie%światła%czerwonego%lub%nawet%bliskiej%podczerwieni.A to z perspektywy dalszego przetwarzania bez odpowiedniego wyczyszczenia takich danych, niesie tylko problemy. Indeksacja tekstu, który zawiera aż tak nieczytelne dane, spowoduje, że będą one równie nieczytelne dla samych metod przeszukujących. Ważne jest aby na tym etapie potrafić dane ocenić pod względem ich jakości oraz w miarę możliwości doprowadzić je do postaci zbliżonej do ideału 😉 Czy na tym etapie warto już wprowadzać modele ML do oceny i poprawy — oczywiście, że tak! Oto przykład działania naszego modelu T5, który czyści teksty z takich sytuacji:
Zdecydowana większość czerwonych karłów należy do typu widmowego M, ale zalicza się do nich także wiele gwiazd późnych podtypów typu widmowego K oraz rzadko występujące, najsłabsze gwiazdy typu L. Maksimum intensywności emitowanego światła przypada w zakresie światła czerwonego lub nawet bliskiej podczerwieni.Może nie idealnie, ale znacznie lepiej od pierwotnej formy 😉
Co zrobić w jeżeli w dokumentach mamy dużo tabel, rysunków/wykresów? Warto rozważyć wykorzystanie modeli, które potrafią je interpretować oraz generować opis, którym następnie można wzbogacić oryginalny tekst.
(…) Ważne jest również identyfikowanie tych dobrych i tych złych jakościowo danych, oraz ich standaryzacja do dalszego przetwarzania.
Indeksowanie danych
To bardzo istotny proces w całym RAGu. Po wstępnej obróbce danych trzeba je zapisać w bazie, w której następnie będą one wyszukiwane. Na tym etapie warto wprowadzić równoległe indeksowanie tekstu zarówno w bazie relacyjnej jak i wektorowej. Baza relacyjna pomoże w ułożeniu dłuższego dokumentu w jego oryginalną strukturę, zaś wektorowa umożliwi semantyczne przeszukiwanie. Bardzo ważnym elementem w procesie indeksowania jest sposób indeksacji. To na tym etapie decydujemy, które informacje z wcześniejszego kroku będą indeksowane, oraz gdzie i jak.
Przede wszystkim należy zastanowić się nad przeznaczeniem systemu RAG (konkretna dziedzina, specjalistyczny agent, ogólne informacje) i dobrać odpowiedni model (embedder), który odpowiednio dobrze „zrozumie” indeksowane treści. To właśnie embedder tworzy wektorowe reprezentacje tekstów, które indeksowane są w bazach wektorowych (np. Milvus), które to następnie są przeszukiwane. Jeżeli na tym etapie transformacja tekstu do wektora będzie niedokładna, czyli innymi słowy, jeżeli źle dobierzemy model embeddera do treści, które indeksujemy, to może to skutkować gorszą/mniej dokładną jakością w procesie ich porównywania. Błąd z indeksowania może zatem być propagowany do dalszych kroków przetwarzania. Ważne jest również dobranie odpowiedniej długości tekstów, które indeksowane są jako pojedynczy fragment. Jeżeli tekst jest za długi, warto podzielić go na mniejsze części zwane chunkami — czyli jeden tekst podzielony jest na kilka mniejszych fragmentów.
Co w sytuacji, kiedy indeksujemy mocno specyficzne treści, do których nie ma dostępnych embedderów? Oczywiście, stajemy przed problemem znalezienia innego, bardziej dopasowanego lub wyuczenia takiego modelu od początku. W jednym z wcześniejszych postów przedstawiliśmy nasz wstępny model embedder, który trenowany był na treściach internetowych.
(…) Istotne jest również dobranie lub wyuczenie specjalistycznego embeddera oraz odpowiednia indeksacja w bazach.
Wyszukiwanie
Można powiedzieć, że sprawa się tutaj nieco upraszcza, ponieważ na etapie wyszukiwania korzystamy z tych samych mechanizmów tłumaczących tekst do reprezentacji wektorowej, co na etapie indeksacji… Nic bardziej mylnego. Dzieje się tak tylko w przypadku, kiedy ograniczamy proces wyszukiwania, tylko do policzenia podobieństwa wektorów reprezentujących pytanie do chunków w bazie. Najczęściej obliczany jest kosinus kąta między wektorem pytania, a wektorami zapisanymi w bazie wektorowej. Tymi wektorami, które zapisaliśmy na etapie indeksowania danych. Jednak, jak wspomnieliśmy wcześniej, zależy jakie informacje indeksujemy, oraz gdzie i jak.
Jeżeli na etapie indeksacji, wzbogacimy informacje o indeksowanych fragmentach o dodatkowe metadane, to właśnie w tym kroku jesteśmy w stanie wstępnie odsiać te chunki, które na 100% są nieprawidłowe. Przykładowo, jeżeli wzbogacimy opis chunku o jego kategorię, wtedy na tym etapie, przed semantycznym porównywaniem za pomocą wyszukiwarki, możemy ograniczyć przestrzeń poszukiwań tylko do tych, które pochodzą ze wskazanej kategorii.
Zatem warto rozważyć opcję, aby semantyczne wyszukiwanie było ograniczane przez dodatkowe wymiary. Czy do tego przydadzą się dodatkowe metody ML? Oczywiście, że tak. To tylko kwestia wyobraźni oraz przeznaczenia danego modelu.
(…) Dodatkowe metainformacje o chunkach mogą mocno pomóc podczas wyszukiwania, np. ograniczenie wyników tylko do dokumentów z określonej kategorii.
Zmiana kolejności rankingu wyników
Ok, a co dalej, jeżeli po odpowiednim filtrowaniu i wyszukaniu informacji nadal mamy problem z wyborem, który z wyszukanych chunków jest najistotniejszy? Wtedy z pomocą nadchodzi proces rerankingowania kolejności wyników zwracanych przez wyszukiwarkę. Jednym ze standardowych podejść jest wykorzystanie modeli typu cross-encoders, które, jeżeli są w odpowiedni sposób nauczone, mogą określić stopień relewantności pytania do wyszukanego chunka. Oczywiście, jak w przypadku embeddera, jeżeli model rerankera nie będzie odpowiednio dobrany do specyfiki danych, wynik może być przeciwny oczekiwanemu 🙂
Co w takiej sytuacji trzeba zrobić? Głównie stosuje się dwa podejścia:
- po lepszym zrozumieniu dziedziny oraz dokładniejszym researchu, bardziej świadomie dobiera się inny,
- lub samemu trenuje się specjalistyczny reranker dostosowany do problemu.
Zarówno jedno jak i drugie podejście ma zalety i wady. Pierwsze z nich jest szybsze, ale (a) nie ma gwarancji, że w ogóle jest taki model, który potrzebujemy, (b) jeżeli godzimy się na jakiś model, to akceptujemy jego dokładność w naszym problemie. Podejście z uczeniem lub douczaniem własnego, raczej będzie dużo bardziej kosztowne, ze względu na czas potrzebny na jego wytworzenie. Jednak jest duża szansa, że taki model będzie dużo dokładniejszy od dostępnych, co podniesie jakość końcowego systemu RAG. Co zatem wybrać? Zależy od sytuacji… 😉
Oczywiście w procesie rerankingowania nie jesteśmy ograniczeni do operowania tylko na modelach cross-encoders, na tym etapie dostajemy potencjalne fragmenty, które zawierają odpowiedź, więc to jedynie nasza wyobraźnia ogranicza nas tutaj z tym, co można zrobić… Czy warto stosować tutaj modele specjalistyczne? Jak najbardziej.
(…) Dopasowanie relewantności chunku do zadanego pytania jest bardzo istotnym krokiem. Nieodpowiednia zmiana kolejności rankingu dokumentów może spowodować, że teksty z istotną informacją zostaną odrzucone tuż przed samym podaniem do GenAI, co mocno może zepsuć końcowy rezultat.
Generowanie odpowiedzi
I w końcu jesteśmy tutaj, czyli na etapie, który na końcowym użytkowniku wywołuje największe wrażenie. Dopiero na tym etapie do gry wchodzi GenAI — jako element konstruujący odpowiedź, która przedstawiana jest jako odpowiedź dla użytkownika systemu RAG.
Wszystkie wspomniane wcześniej kroki, to potok preprocessingu danych, wyszukania, selekcji i określenie relewantności cząstkowych wyników do zapytania użytkownika. To właśnie te kroki w bardzo dużym stopniu determinują czy końcowa odpowiedź będzie na temat, czy nie. Źle dobrane dane na tym etapie spowodują efekt halucynacji modelu GenAI. Ważne jest również, aby model GenAI, który wykorzystujemy do generowania odpowiedzi był również odpowiednio douczony w zadaniu odpowiadania na pytania. Mówiąc o GenAI, raczej myślimy o modelach instrukcji. Ważne zatem jest, aby taki GenAI nie tylko rozumiał język, potrafił w tym języku odpowiadać, ale również odpowiednio reagować na instrukcję. To jego zadaniem będzie podsumowanie wszystkich fragmentów/chunków zwróconych z wcześniejszych kroków. Więc ważne, aby taki model przede wszystkim potrafił reagować na instrukcje odpowiadania na pytania, na podstawie dostarczonego kontekstu w postaci chunków.
Warto pamiętać o jeszcze jednej, istotniej kwestii takich modeli, mianowicie wielkości wejścia. Każdy model ma określoną wielkość wejścia. Wielkość wejścia oznacza ile danych, mierzonych w liczbie tokenów, taki model jest w stanie przetworzyć. Jeżeli do modelu podamy za dużo danych, najprawdopodobniej będą one pomijane — a tego nie chcemy w RAGu, gdzie przeszukujemy potężne kolekcje i równie dużo odpowiedzi możemy dostać!
Modele instrukcji, to przeważnie bardzo duże modele, zaczynając od tych mniejszych 8B (miliarów), przez 70B, 405B i więcej parametrów. W takim razie stajemy przed kolejnym pytaniem — model u siebie, czy model w chmurze? Oczywiście wszystko zależy od przeznaczenia systemu oraz możliwości przesyłania danych przez internet do serwisów zewnętrznych takich jak ChatGPT. Jeżeli wybór pada na model generatywny odpytywany lokalnie, pozostaje kwestia jak we wszystkich wcześniejszych krokach…. odpowiedni model do wybranego problemu 🙂 A jaki model? To już osobne opowiadanie.
(…) Wcześniejsze kroki są istotne, ale równie istotny jest odpowiedni dobór GenAI, który generował będzie końcową odpowiedź. To on może popsuć całe wrażenie.
Zakończenie
Poskładajmy całość do kupy 😉
Można zatem śmiało powiedzieć, że jakość odpowiedzi z takiego systemu, jest mocno determinowana jakością danych, z których taki system korzysta. Ważne jest również identyfikowanie tych dobrych i tych złych jakościowo danych, oraz ich standaryzacja do dalszego przetwarzania. Istotne jest również dobranie lub wyuczenie specjalistycznego embeddera oraz odpowiednia indeksacja w bazach. Dodatkowe metainformacje o chunkach mogą mocno pomóc podczas wyszukiwania, np. ograniczenie wyników tylko do dokumentów z określonej kategorii. Dopasowanie relewantności chunku do zadanego pytania jest bardzo istotnym krokiem. Nieodpowiednia zmiana kolejności rankingu dokumentów może spowodować, że teksty z istotną informacją zostaną odrzucone tuż przed samym podaniem do GenAI, co mocno może zepsuć końcowy rezultat. Wcześniejsze kroki są istotne, ale równie istotny jest odpowiedni dobór GenAI, który generował będzie końcową odpowiedź. To on może popsuć całe wrażenie.
PPS.
A już niebawem opublikujemy nasz model GenAI — pLLama, model LLama douczony na język polski 🙂
Pingback: pLlama3 (8B + 70B) – GenAI dla polskiego – RadLab
Pingback: Czy można w prosty sposób wprowadzić bazę wiedzy dla GenAI? – RadLab